Sutskever et al. (2014) - Encoder-Decoder Architectures
The encoder-decoder framework, introduced by Sutskever et al. (2014), enabled end-to-end sequence-to-sequence learning for tasks like machine translation.
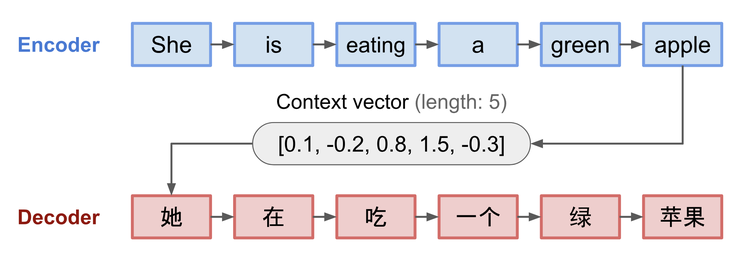
The encoder-decoder architecture, introduced in 2014 by Ilya Sutskever, Oriol Vinyals, and Quoc Le, marked a major advancement in modeling variable-length sequence pairs. First applied to machine translation, the approach established a general pattern for tasks where an input sequence must be transformed into an output sequence,such as summarization, question answering, and code generation.
It laid the groundwork for innovations like attention mechanisms , Transformers , BERT , and T5 .
Historical Context
Prior to this model, most NLP systems were built on hand-engineered pipelines. While RNNs and LSTMs could process sequences, they struggled with tasks that required learning mappings between distinct input and output sequences of varying lengths.
Sutskever et al. demonstrated that a two-part network trained with backpropagation could learn these mappings end-to-end. The encoder compresses the input into a context vector, and the decoder unfolds that into an output sequence.
Technical Summary
The architecture consists of:
- Encoder: Processes input sequence and outputs a fixed-size context vector (hidden state)
- Decoder: Uses this vector to generate the output sequence step by step
Both components are typically implemented as RNNs or LSTMs in early models, with weights learned jointly. At inference, decoding is performed autoregressively,each prediction conditions on previous outputs.
Challenges:
- Performance degrades on long sequences due to the bottleneck of the fixed-size context vector
- No dynamic alignment between input and output tokens
These limitations motivated the introduction of attention , which allows the decoder to access the full sequence of encoder outputs.
Impact and Legacy
Encoder-decoder models became the default architecture for sequence-to-sequence tasks. They underpin:
- Machine translation (e.g., Google Translate)
- Text summarization and dialogue systems
- Automatic speech recognition
- Generative models like T5 and diffusion transformers
Even with the rise of decoder-only architectures like GPT , encoder-decoder patterns persist, especially where bidirectional understanding of input is essential.
Related Work
- Attention Mechanisms : Enhanced encoder-decoder capabilities
- Transformers : Extend the encoder-decoder template with self-attention
- LSTM : Core component of early encoder-decoders
- BERT : Encoder-only adaptation
- GPT : Decoder-only variant
Further Reading
- Sutskever, I., Vinyals, O., & Le, Q. V. (2014). Sequence to Sequence Learning with Neural Networks. NeurIPS.
- Cho, K. et al. (2014). Learning Phrase Representations using RNN Encoder–Decoder for Statistical Machine Translation.
- Evolution of Model Architectures overview
- Tags:
- Papers
- Architectures