Radford et al. - Generative Pretrained Transformers (GPT)
OpenAI's GPT series expanded the Transformer architecture into a generative paradigm, introducing large-scale pretraining followed by task-specific fine-tuning.
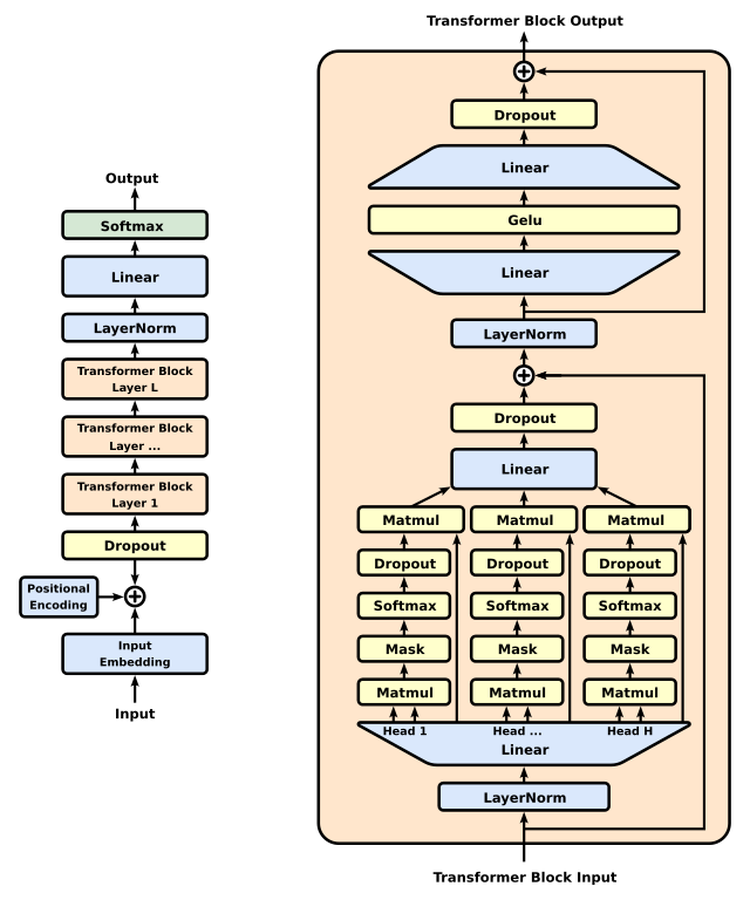
The Generative Pretrained Transformer (GPT) series, introduced by OpenAI beginning in 2018, transformed the landscape of natural language processing. GPT models demonstrated that large-scale unsupervised pretraining on diverse text corpora, followed by light supervised fine-tuning, could produce high-performance models for a wide range of language tasks.
Each generation - from GPT-1 to GPT-4 - scaled up model size, training data, and capabilities, establishing the pretrain-then-finetune paradigm that now dominates AI.
Historical Context
GPT builds directly on the Transformer architecture introduced by Vaswani et al. (2017), but adopts a decoder-only design. It also inherits the idea of language modeling as a pretext task: predict the next token given previous ones.
OpenAI’s GPT-1 (2018) paper, Improving Language Understanding by Generative Pretraining, was a proof of concept. GPT-2 (2019) scaled this up and sparked controversy due to its capacity to generate plausible and coherent text. GPT-3 (2020) further pushed scale to 175 billion parameters and demonstrated few-shot learning via prompting.
Technical Summary
GPT models are based on the Transformer decoder stack, with causal (unidirectional) self-attention masking to ensure that each token attends only to previous tokens. Key design features include:
- Autoregressive objective: Predict the next token in a sequence
- Layer normalization, residuals, and feedforward layers: As in original Transformers
- Positional encodings: Inject order information into token embeddings
Training occurs in two phases:
- Pretraining on a large corpus (e.g., web text, books, code)
- Fine-tuning (or prompting) on specific tasks or via alignment (e.g., RLHF)
Notable Milestones:
- GPT-1: 117M parameters; BookCorpus
- GPT-2: 1.5B parameters; WebText
- GPT-3: 175B parameters; diverse internet-scale data
- GPT-4: Multimodal capabilities, safety alignment, emergent reasoning
Impact and Capabilities
GPT models can:
- Write essays, poems, and code
- Summarize or translate documents
- Answer questions and perform dialogue
GPT-3 demonstrated that scale itself acts as a form of meta-learning, enabling few-shot and zero-shot generalization without task-specific optimization. GPT-4 added multimodal input and improved alignment.
The GPT series popularized the foundation model concept and catalyzed a wave of generative tools across industries.
Related Work
- Transformers : Architectural foundation
- BERT : Contrast with masked, bidirectional pretraining
- Encoder-Decoder Architectures : GPT uses decoder-only design
- Attention Mechanisms : Core to autoregressive generation
Further Reading
- Radford et al. (2018). Improving Language Understanding by Generative Pretraining.
- Radford et al. (2019). Language Models are Unsupervised Multitask Learners (GPT-2).
- Brown et al. (2020). Language Models are Few-Shot Learners (GPT-3).
- OpenAI (2023). GPT-4 Technical Report.
- Evolution of Model Architectures overview
- Tags:
- Papers
- Architectures