Hochreiter & Schmidhuber (1997) - Long Short-Term Memory (LSTM)
LSTM networks, introduced by Hochreiter and Schmidhuber in 1997, solved the vanishing gradient problem and became the dominant architecture for sequence modeling prior to Transformers.
The Long Short-Term Memory (LSTM) architecture, introduced by Sepp Hochreiter and Jürgen Schmidhuber in 1997, was a breakthrough in solving one of the biggest problems in training neural networks on sequential data: the vanishing gradient problem. Prior to LSTMs, recurrent neural networks (RNNs) struggled to retain information across long sequences, making them ineffective for many natural language and time-series tasks.
LSTM introduced a memory cell and gating mechanisms that allowed information to persist or be forgotten over time. This innovation paved the way for practical sequence modeling before being eventually overtaken by Transformers .
Historical Context
Standard RNNs had been known since the 1980s but were plagued by instability during training. Gradients would either vanish or explode as they were propagated back through time, making it difficult to learn long-range dependencies.
Hochreiter’s 1991 dissertation first formalized the vanishing gradient issue, and the 1997 LSTM paper provided a practical architectural solution. Over time, LSTMs became the de facto standard for sequence tasks like speech recognition, language modeling, and machine translation - often trained using backpropagation through time (BPTT).
Technical Summary
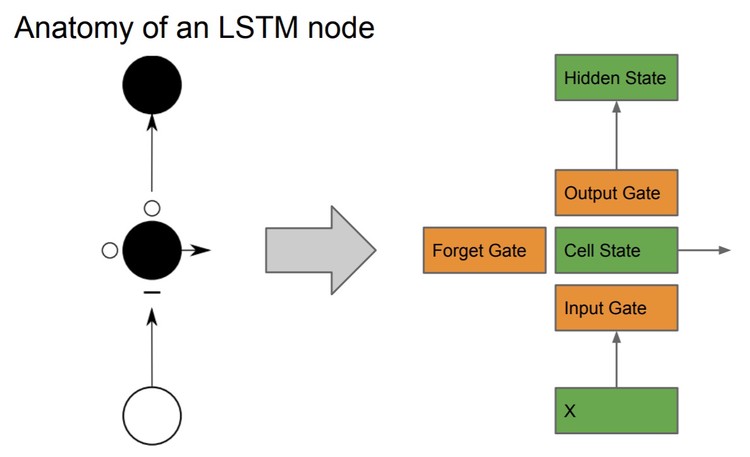
LSTMs extend traditional RNNs by introducing a memory cell and three gates:
- Input gate: Controls how much of the new input to store in memory
- Forget gate: Decides what information to discard from the cell
- Output gate: Determines how much of the memory to expose as output
These gates are implemented using learned weights and sigmoid activations, which scale values between 0 and 1. The memory cell acts as an accumulator of state information over time.
Key Benefits:
- Mitigates vanishing gradients: Maintains stable gradients over long sequences
- Captures long-range dependencies: Crucial for language, audio, and time-series data
- Modular: Can be stacked into deep recurrent networks
Applications and Impact
LSTMs powered major advances in NLP and speech systems from the late 2000s through the mid-2010s:
- Google Voice Search and translation
- Handwriting and speech recognition
- Time-series forecasting and anomaly detection
They were also foundational in early encoder-decoder architectures , such as the sequence-to-sequence model from Sutskever et al. (2014), where LSTMs encoded input sequences and decoded output sequences.
Transition to Attention
Although LSTMs reigned for nearly two decades, their sequential nature limited parallelism and scalability. The introduction of attention mechanisms and ultimately Transformers offered superior performance and efficiency on large-scale tasks.
Yet many of the problems LSTMs solved - particularly temporal dependency and memory - remain relevant in evaluating modern models.
Related Work
- Backpropagation : Used in training LSTMs via BPTT
- Encoder-Decoder Architectures : Early applications of LSTMs
- Transformers : Replaced LSTMs as the dominant sequence model
Further Reading
- Hochreiter, S., & Schmidhuber, J. (1997). Long Short-Term Memory. Neural Computation, 9(8), 1735–1780.
- Gers, F. A., Schmidhuber, J., & Cummins, F. (2000). Learning to forget: Continual prediction with LSTM. Neural Computation.
- Evolution of Model Architectures overview
- Tags:
- Papers
- Architectures